Implementing Flash Attention
This article is targeted towards people with good understanding of Machine Learning and Attention, who are new to Triton, Flash Attention or GPU programming.

Understanding the Fundamentals
What is Flash Attention?
Flash Attention is a memory-efficient algorithm that speeds up attention computation by reducing data transfers between GPU Memory hierarchies. This is achieved by restructuring attention calculations into smaller blocks that fit in fast SRAM, reducing memory bottlenecks and making training of larger models with longer sequences possible.
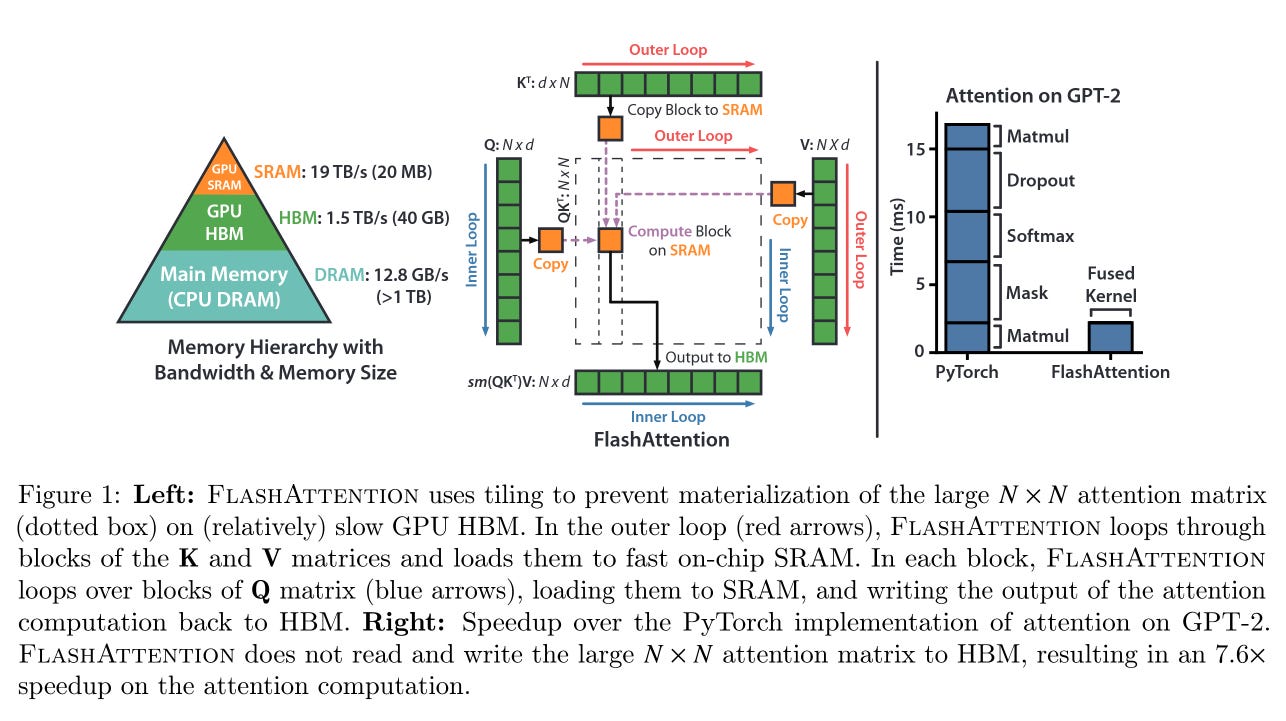
Flash Attention consists of two primary optimization parts:
First, we use mathematical operations to reformulate the equations of the Softmax formula, reducing the required global memory reads and writes from three steps to just two, which significantly improves computational efficiency. We call this online softmax. This is done by tracking the maximum value in each row and updating the normalizing factor when a new maximum is found. When a new maximum is encountered, we multiply all previous partial sums by e^(previous_max - new_max).
Second, we optimize the matrix multiplication through parallelization using Block Matrix Multiplication. This technique divides the Query, Key, Value, and Output Matrices into blocks of power-of-2 sizes. As the Softmax is applied in each block independently, we need to recalculate the Softmax for the whole row after Q and K^T block multiplication. This operation can be improved if instead we used the online Softmax algorithm.
GPU Threading Architecture
On regular CPU cores the L1 Cache is shared among the (usually 2) threads and they can be independently run instructions. Meanwhile the "threads" on Nvidia GPUs are grouped by 32 (in AMD it's 64). GPU threads in the same grouping (called warp by NVIDIA and wavefront by AMD) run the same instructions simultaneously. Here instruction means an operation - i.e. add, multiply, etc. But each thread in a warp can run the operation with its own DATA. Some threads can be masked out and no operation to be performed with them if needed.
Parallelizing Operations on GPUs
Typical NVIDIA GPUs have in the order of ~2000 threads. In case where we want to do for example for N=1'000'000 data points the same operation at once, we should do the following.
First, split the elements into blocks of 32, so we have ceil(N/32) blocks
int num_blocks = ceil((float)N / block_size);
printf("Vector Add - N: %d will be processed by %d blocks of size %d\n", N, num_blocks, block_size)
dim3 grid(num_blocks, 1, 1);
dim3 block(block_size, 1, 1);
Then we call the kernel, which looks the following way
cuda_vector_add_simple<<<grid, block>>>(d_OUT, d_A, d_B, N);
...
__global__ void cuda_vector_add_simple(EL_TYPE *OUT, EL_TYPE *A, EL_TYPE *B, int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N)
{
OUT[i] = A[i] + B[i];
}
}
The thread has only its Thread ID as unique information, therefore we must use it so that each thread does the operations on its part of the data. The if statement is needed so that if the remaining items to be calculated in last block is less than the number of threads per block, no calculation would happen.
For example we have 50 as input for N. We would get ceil(50/32) = 2 blocks. Which means CUDA will call 2 warps and for the second one only 18 threads will need to execute the calculation, The remaining 14 (i from 50 up to 63) will not as we don't have data for them.
Similar mathematics using the Thread ID is used for example if we want to make a matrix operation. We should point out that the matrix is flattened in C/C++ (CUDA as well) in memory's index - i.e. it is stored by NUM_COLS times consecutive NUM_ROWS (i.e. row-major layout):
int num_blocks_ROWS = (NUM_ROWS + ROWS_block_size -1) / ROWS_block_size; //this is same as ceil(NUM_ROWS / ROWS_block_size)
int num_blocks_COLS = (NUM_COLS + COLS_block_size -1) / COLS_block_size; //this is same as ceil(NUM_COLS / COLS_block_size)
printf("Matrix Add - M: %d, N: %d will be processed by (%d x %d) blocks of size (%d x %d)\n", NUM_ROWS, NUM_COLS, num_blocks_ROWS, num_blocks_COLS, ROWS_block_size, COLS_block_size);
dim3 grid(num_blocks_COLS, num_blocks_ROWS, 1);
dim3 block(ROWS_block_size, ROWS_block_size, 1);
cudaEvent_t start_kernel, stop_kernel;
CUDA_CHECK(cudaEventCreate(&start_kernel));
CUDA_CHECK(cudaEventCreate(&stop_kernel));
__global__ void cuda_matrix_add_simple(EL_TYPE *OUT, EL_TYPE *A, EL_TYPE *B, int NUM_ROWS, int NUM_COLS)
{
int row_index = blockIdx.y * blockDim.y + threadIdx.y;
int col_index = blockIdx.x * blockDim.x + threadIdx.x;
if (row_index < NUM_ROWS && col_index < NUM_COLS)
{
size_t index = static_cast<size_t>(row_index)*NUM_COLS + col_index; // A[row_index][col_index]
OUT[index] = A[index] + B[index];
}
}
Implementation Triton
Introduction to Triton
Triton is an open-source GPU programming language and compiler. It simplifies writing GPU code without expertise in CUDA. Triton includes a Python client library and backend, which is what we are going to use.
In Triton the kernel is working with a group of elements with size BLOCK_SIZE, not with individual elements like in CUDA.
Optimizing Performance with Autotuning
Basically, Triton doesn't know what is the best configuration of these parameters. num_warps is the number of warps that run together. For each different [SEQ_LEN, HEAD_DIM] combination triton runs the different configurations provided and remembers which one runs in optimal time for the specific paramters
@triton.autotune(
[
triton.Config(
{"BLOCK_SIZE_Q": BLOCK_SIZE_Q, "BLOCK_SIZE_KV": BLOCK_SIZE_KV},
num_stages=num_stages,
num_warps=num_warps,
)
for BLOCK_SIZE_Q in [64, 128]
for BLOCK_SIZE_KV in [32, 64]
for num_stages in ([3, 4, 7])
for num_warps in [2, 4]
],
key=["SEQ_LEN", "HEAD_DIM"]
)
Software Pipelining for Asynchronous Operations
It is mainly used for for loops, when they can be run asynchronously. The main drawback is that when multiple instances run at the same time it requires more memory. num_stages is how many asynchronous operations we want to have at the same time. So we expect the process to take num_stages times more memory, but also run num_stages times faster. It is considered optimal to have number of iterations in the loop to be a lot larger than num_stages.
Full implementation with Triton
The rest of the code provided matches with the Flash Attention steps for calculations in the Flash Attention 2 paper.
If you want to see my full implementation, see this repo folder:
https://github.com/ipdimitrov/machine-learning/tree/main/flash-attention
Thank you for reading!
Sources:
https://arxiv.org/pdf/2205.14135
https://arxiv.org/abs/2307.08691
https://triton-lang.org/main/getting-started/tutorials/06-fused-attention.html
https://github.com/hkproj/triton-flash-attention